
Поиск в таблице
Поиск в таблице
Перечисленные выше операции с таблицей предполагают, что для однозначного доступа к ее элементам последние должны содержать один или более признаков, отличающих их от других элементов этой таблицы. С этой целью в логическую структуру элемента включается по крайней мере одно поле — ключ, содержимое которого уникально для любого из элементов, входящих в таблицу. В общем случае работа с таблицами сводится к методам решения задачи поиска нужного элемента таблицы по заданному значению ключа. Результат решения — получение адреса искомого элемента или заключение о его отсутствии. Для локализации элемента таблицы необходимо знать два адресных компонента — адрес таблицы и смещение нужного элемента относительно начала таблицы. Адрес таблицы получить несложно, так как он является адресом ее первого элемента. Что же касается определения второй компоненты адреса, то для этого существует ряд методов, рассмотрению которых и будет посвящено дальнейшее изложение.
В ряде случаев наряду с ключевым полем определяют еще одно служебное поле — поле текущего состояния элемента, которое может принимать три значения:
Целесообразность использования поля текущего состояния элемента будет видна из дальнейших рассуждений.
С точки зрения организации поиска таблицы делятся на:
Неупорядоченные таблицы
Это простейший вид организации таблиц. Элементы располагаются непосредственно друг за другом, без пропусков. Процесс поиска нужного элемента выполняется очень просто — последовательным перебором элементов таблицы начиная с первого. При этом анализируется ключевое поле и в случае удовлетворения его условию поиска нужный элемент локализуется. Такой способ поиска называется последовательным, или линейным. Для добавления нового элемента необходимо найти первое свободное место, после чего выполнить операцию добавления. Процесс удаления можно реализовать следующим образом. После локализации нужного элемента его поле текущего состояния необходимо установить в состояние «элемент удален». Тогда процесс поиска места для добавления нового элемента будет заключаться в поиске такого элемента, у которого поле текущего состояния элемента имеет значение «элемент удален» или «элемент свободен». Можно еще более оптимизировать работу с неупорядоченной таблицей путем введения в начале таблицы (или перед ней) дескриптора, поля которого содержали бы информацию о размере таблицы, положении первого свободного элемента и т. д.
Обычно неупорядоченные таблицы используют в качестве временных для хранения небольшого количества элементов (до 20). Для таблиц большего размера такая организация поиска неэффективна, поэтому для них следует применять другие способы локализации нужного элемента.
Приемы работы с неупорядоченной таблицей продемонстрируем на примере следующей задачи. Необходимо прочитать содержимое файла maket.txt и обо всех десятичных и шестнадцатеричных числовых константах собрать информацию о значении константы и номере строки, в которой данная константа встретилась. Вывести информацию о десятичных константах на экран. Для того чтобы избежать возни с несущественными деталями, введем следующие ограничения:
Поле текущего состояния представляет собой запись, битовые поля которой означают следующее:
:prg02_05.asm - программа на ассемблере демонстрации работы с неупорядоченной таблицей ;Вход: файл maket.txt с идентификаторами, среди которых присутствуют десятичные
и шестнадцатеричные константы. ;Выход: вывод информации о десятичных константах на экран.
state_tab struc
last_off dw 0 ;адрес первого байта за концом таблицы
elem_free dw 0 ;адрес первого свободного элемента (Offffh - все занято)
ends
constant struc
state db 0 ;поле состояния элемента таблицы
db 02dh форматирование вывода на экран key db 10 dup (' ') :ключ. он же значение константы
db 02dh форматирование вывода на экран
line db 2 dup (' ') :строка файла, в которой встретилась константа endjine db Odh.Oah.'S' :для удобства вывода на экран ends .data
s_tab state_tab <> tab constant 19 dup (<>)
constant <8.> последний элемент таблицы - бит 3=1 end_tab=$-tab
filename db 'maket.txf.0 handle dw 0 : дескриптор файла buf db 240 dup С ') xlat_tab db Odh dup (OO).Odh ;признак конца строки
db 'O'-Oeh dup (0)
db ':'-'0'+l dup CO') ;признак цифры 0..9
db 'H'-':' dup (0). " :признак буквы 'Н'
db 'h'-'H' dup (0). 'h' ;признак буквы 'h' db Offh-'h1 dup (00)
curjine db 0
.code
:открываем файл mov ah. 3dh
movdx,offset filename
int 21h
jc exit :ошибка (cf=l)
mov handle.ax ;читаем файл:
movah.3fh :функция установки указателя
mov bx,handle
mov ex,240 ;читаем максимум 240 байт
lea dx.buf
int 21h
jc exit
mov ex.ax фактическая длина файла в сх инициализируем дескриптор таблицы s_tab
lea si.tab :адрес таблицы в si
mov s_tab.elem_fгее.si ;первый элемент таблицы - свободен
add si .end_tab
mov s_tab.last_off,si :адрес первого байта за концом таблицы
lea bx.xlat_tab
leadi. buf
cканируем до первого пробела: push ds popes
cycll: mov al. ' ' repne scasb -.сканирование до первого пробела
jcxz displ .цепочка отсканирована -> таблица заполнена push сх :классифицируем символ после пробела (команда XLAT):
mov al.[di]
xlat
emp al. '0':первый символ после пробела - 0
je ml
cmpal.Odh :первый символ после пробела - Odh
je m2 :все остальное либо идентификаторы, либо неверно записанные числа
pop сх
jmpcycll ml: :первый символ после пробела - 0..9:
mov si.di ;откуда пересылать
fmov al. ' ' push di repne scasb сканирование до первого пробела mov cx.di dec ex subcx.si ;сколько пересылать lea di.tab emp s__tab.elem_free.0ffffh :есть свободные элементы? je displ : свободных элементов нет
mov di,s_tab.elem_free :адрес первого свободного элемента push di
lea di.[di].key rep movsb ;пересыпаем в элемент таблицы
deed! ;Какого типа это константа?
emp byte ptr [di].'h' popdi
je m4
and [di].state.Ofbh ;десятичная константа
jmp $+5 m4: or [di].state.100b ;шестнадцатеричная константа
mov al ,cur_line :текущий номер строки в al
aam преобразуем в символьное представление
or ah.030h
mov [di].line,ah
or al.030h
mov [di+1].line.al :и в элемент таблицы
or [di].state.lb ;помечаем элемент как используемый
:теперь нужно поместить в поле s_tab. elem_free адрес нового свободного элемента пб: emp di. s_tab. 1 ast_of f
ja displ
add di.type constant :к следующему элементу
test [di].state.lb
jnz m5 ; используется => к следующему элементу
mov s_tab.elem_fгее.d i pop di pop ex
jmpcycU m2: увеличить номер строки
inc cur_line
jmp cycl 1 displ: :отображение на экране элементов таблицы
lea di .tab m6:
test [di].state.100b
jnz m7 :выводим на экран строку
mov ah.9
mov dx.di
int 21h ml: add di. type constant
emp di ,s_tab.last_off
jb m6
В этой программе показаны основные приемы работы с неупорядоченной таблицей. Усложнить данную программу можно, например, дополнив набор сведений о каждой константе информацией о ее длине. Далее можно попрактиковаться в этом вопросе, поставив себе задачу удалить из таблицы данные о нулевых константах (обоих типов — 0 и 0h) и вывести окончательное содержимое таблицы на экран. В качестве ключа для доступа к ячейке таблицы можно использовать значение самой константы (размером 10 байт).
Обратите внимание на еще два момента, отраженные в этой программе.
Древовидные таблицы
Древовидные таблицы являются несколько улучшенным вариантом неупорядоченных таблиц. Новые записи в древовидную таблицу по-прежнему поступают неупорядоченно. Но на этот раз место, занимаемое этими записями среди других записей в таблице, определяется значением ключевого поля. Принцип здесь такой же, как и в сортировке с помощью дерева (см. материал выше).
В общем случае каждая запись в древовидной таблице сопровождается двумя указателями (Рисунок 2.7): один указатель хранит адрес записи с меньшим значением ключа (адрес узла-предка), второй — с большим (адрес узла-сына).
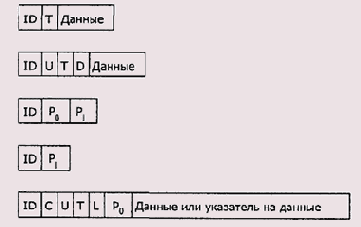
Рисунок 2.7. Древовидная организация таблицы
Процесс добавления нового элемента в древовидную таблицу производится следующим образом. Значение ключа нового элемента сравнивается со значением ключа первого элемента дерева. По результатам сравнения ключей новый элемент «поступает» в левое или правое поддерево первого элемента дерева. Далее процесс сравнения и поступления в левое или правое поддерево очередного узла продолжается аналогичным образом и до тех пор, пока не будет найден пустой элемент в нужном направлении просмотра. Новая запись помещается в данный пустой элемент, при этом настраивается указатель с адресом узла-предка.
Преимущества древовидной структуры таблицы проявляются на этапе поиска нужного элемента. Сам процесс подобен действиям на этапе вставки нового элемента в таблицу, являясь при этом в отличие от неупорядоченного поиска целенаправленным. Поиск прекращается либо при совпадении ключевого поля, либо при обнаружении пустого указателя, то есть это означает, что нужного элемента в таблице нет.
Самое сложное в использовании древовидных таблиц — реализация процесса удаления элементов, так как при этом необходимо производить их переупорядочивание.
Реализовать таблицу древовидной организации можно как с использованием полей указателей (см. выше), так и без них. Если отказаться от полей указателей, то таблица может представлять собой массив из п структур, которые пронумерованы от 0 до п-1. Тогда структура с ключом, соответствующим корню дерева, должна располагаться на месте структуры с номером m = [(n-1)/2], где скобки [] означают целую часть от деления. Соответственно левое поддерево будет располагаться в левом подмассиве (элементы 0..m-1), а правое — в правом подмассиве (элементы m+1..n-1). Корень левого поддерева — элемент ш,' - [(m-1)/2], корень правого поддерева — элемент mr = [т+1+(п-1)/2] и т. д. Этот способ экономичнее с точки зрения расходования памяти, но сложнее алгоритмически. Предполагается, что соответствующее таблице дерево сбалансировано и максимальное количество элементов в таблице известно.
Наглядный пример организации древовидной таблицы — расстановка слов в лексикографическом порядке. Эта операция выполняется с помощью лексикографических деревьев, понятие о которых приведено ниже — в разделе, посвященном деревьям. Там же приведен соответствующий пример.
Упорядоченные таблицы
Работа с таблицей оказывается более эффективной, если элементы в ней некоторым образом упорядочены. Наиболее часто таблица упорядочивается по значению ключевого поля. Но не исключено и использование другого принципа упорядочивания, к примеру по частоте обращения к элементам таблицы и т. п. Упорядочивание таблицы и последующий поиск в ней производится методами, рассмотренными выше. Порядок выполнения этих и других операций с упорядоченной по значению ключа таблицей рассмотрим на следующем примере.
Пусть необходимо запомнить элементы таблицы информацией о 10 словах, вводимых с клавиатуры. Длина слов — не более 20 символов. Структура элемента таблицы следующая: поле с количеством символов в слове; поле с самим словом. После ввода информации о словах необходимо упорядочить элементы таблицы по признаку длины слов. Затем вывести на экран элемент таблицы, содержащий первое из слов длиной 5 символов, удалить этот элемент из таблицы и вставить в нее новое слово, введенное с клавиатуры.
При такой постановке задачи нам придется решить весь комплекс проблем, возникающих при работе с упорядоченными таблицами.
:prg02_06.asm - программа на ассемблере демонстрации работы с упорядоченной таблицей
;Вход: 10 слов, вводимых с клавиатуры. Длина слов - не более 20 символов.
;Выход: вывод на экран элемента таблицы, содержащего первое из слов длиной 5 символов,
удаление этого элемента из таблицы и вставка в нее нового слова, введенного с
клавиатуры.
element tab struc
lendb 0 -.длина слова
simvjd db 20 dup (20h) :само слово
ends
0длина введенного слова (без учета 0dh) К db 21 dup (20h) -.буфер для ввода (с учетом 0dh)регистры
lea si.in_str -.откуда пересылать
Tea di out_str ;куда пересылать
movcx.lenjnovs -.сколько пересылать repmevsb ; пересылаем строку восстанавливаем регистры
tabelement._tab 10 dup (<>)
len_tab=$-tab
buf buf_0ah<>
key db 5
nrev element tab <> ;предыдущий элемент
Г element tab" <> временная переменная для сортировки
.code
leadi.tab lea si .buf . bufjn mov ex. 10 lea dx. buf movah.Oah push ds
mh ;вводим слова с клавиатуры в буфер buf
-.сохраняем регистры .........
intZlh
move1, buf. lenjn
mov [di].len.cl ;длина слова -> tab.length
adddi ,simv id
repmovsb -.пересылка слова в элемент таблицы :восстанавливаем регистры .........
adddi.type element_tab
;Упорядочиваем таблицу методом пузырьковой сортировки
п-10
mov cx.n-1
mov si .1
@@сус11: :внешний цикл - по 1 push ex
subcx'.S! количество повторений внутреннего цикла push si временно сохраним 1 - теперь о=п
mov si .n-1
@@cyc!2: push si
movax.type element_tab
mul si
mov si.ax
mov di .si
sub di.type element_tab :в di адрес предыдущей записи
mov al.[di].len
cmp [si].len.al сравниваем последующий с предыдущим
ja @@ml ;обмениваем
s_movsbx.[di].<type element_tab> :x=mas[j-l]
s_movsb[di].[si].<type element_tab> ;mas[j-l]»mas[j] ;mas[j]=x push ex
mov ex.type element_tab :сколько пересылать
mov di ,si
lea si.x юткуда пересылать repmovsb : пересылаем строку pop ex @@ml: pop si
dec si :цикл по j с декрементом n-i раз
loop @@cycl2 pop si
inc si pop ex
dec ex
jcxz in2
jmp @@cycl 1
m2: ;ищем элемент путем двоичного поиска :в si и di индексы первого и последнего элементов последней просматриваемой части
последовательности;
mov si.0
mov di.n-1
;получим центральный индекс: cont_search: cmp si .di :проверка на окончание (неуспешное):si>di
ja exit
mov bx.si
add bx.di
shr bx.l ; делим на 2 push bx
movax.type element_tab
mul bx
mov bx.ax
mov al.key :искомое значение в ах
cmp [bx].Ten.al сравниваем с искомым значением
je @@rn4 ; искомое значение найдено
ja ШтЗ :[bx].len>k ;[bx].len<k: popbx
mov si ,bx
inc si
jmpcont_search @@m3: pop bx :1
mov di .bx
dec di
jmp cont_search @@m4: movax.type element_tab
mul si
mov si.ax
: конец поиска - в si адрес элемента таблицы со словом длиной 5 байт :выводим его на экран :преобразуем длину в символьный вид:
mov al, [si]. Ten
хог ex.ex
movcl.al ;длина для movsb
aam
or ах. ;в ах длина в символьном виде
mov buf. 1 en_buf.ah
mov buf .lerMn.al push si :сохраним указатель на эту запись
add si .simvjd
lea di .buf.buf_in rep movsb
mov byte ptr [di].'$' :конец строки для вывода 09h (int 21h) :теперь выводим:
lea dx.buf
mov ah.09h
int 21h
:удаляем запись pop si :-i- восстановим указатель на удаляемую запись
mov di .si
add si .type element_tab
mov cx.len_tab
sub ex.si ;в сх сколько пересылать rep movsb :обнуляем последнюю запись
xor al .al
mov ex.type element_tab rep stosb
:вводим слово с клавиатуры: insert: ;вводим слово с клавиатуры lea dx.buf mov ah.0ah int21h :c помощью линейного поиска ищем место вставки, в котором выполняется условие buf.1еn_
in=<[si].Ten
lea si.tab
mov al .buf.len_in @@m5: emp al,[si].Ten
jbe @@m6
add si .type element_tab
jmp @@m5
@@m6: push si сохраняем место вставки :раздвигаем таблицу, последний элемент теряется
add si.type element_tab
mov cx.len_tab
sub ex.si ;сколько пересылать std
lea si .tab
add si , lentab
mov di.si
sub si.type element_tab rep movsb eld
;формируем и вставляем новый элемент pop di восстанавливаем место вставки :обнуляем место вставки push di
хог al .al
mov ex.type element_tab rep stosb popdi
lea si ,buf .bufjn
mov cl .buf .lenjn
mov [di].len,cl
add di ,simv_id rep movsb
Таблицы с вычисляемыми входами
Ранее мы отмечали, что скорость доступа к элементам таблицы зависит от двух факторов — способа организации поиска нужного элемента и размера таблицы. Для маленьких таблиц любой метод доступа будет работать быстро. С ростом размера таблицы выбор способа организации доступа приходится производить прежде всего исходя из критерия скорости локализации нужного элемента таблицы. Элементы таблицы отличаются друг от друга уникальным значением ключевого поля. При этом ключевыми могут являться не только одно, но и несколько полей элемента таблицы. Ключ, в том числе и символьный, в памяти представляется последовательностью двоичных байт. Исходя из того что ключ уникален, соответствующая двоичная последовательность также будет уникальной. А нельзя ли использовать это уникальное значение ключа для вычисления адреса местоположения элемента в таблице? Оказывается, можно, а в ряде приложений это оказывается очень эффективно, так как в идеальном случае доступ к нужному элементу таблицы осуществляется всего за одно обращение к памяти. С другой стороны, на практике часто возникает необходимость размещения элементов таблицы с достаточно большим диапазоном возможных значений ключевого поля, в то время как программа реально использует лишь небольшое подмножество значений этих ключей. Например, значение ключевого поля может быть в диапазоне 0..3999, но задача постоянно использует не более 50 значений. В этом случае крайне неэффективным было бы резервировать память для таблицы размером в 4000 элементов, а реально использовать чуть больше 1 % отведенной для нее памяти. Гораздо лучше иметь возможность воспользоваться некоторой процедурой, отображающей задействованное пространство ключей на таблицу размером, близким к значению 50. Большинство подобных задач решается с использованием методики, называемой хэшированием. Ее основу составляют различные алгоритмы отображения значения ключа в значение адреса размещения элемента в таблице. Непосредственное преобразование ключа в адрес производится с помощью функций расстановки, или хэш-функций. Адреса, получаемые из ключевых слов с помощью хэш-функций, называются хэш-адресами. Таблицы, для работы с которыми используются методы хеширования, называются таблицами с вычисляемыми входами, хэш-таблицами, или таблицами с прямым доступом.
Основополагающую идею хэширования можно пояснить на следующем примере. Предположим, необходимо подсчитать, сколько раз в тексте встречаются слова, первый символ которых — одна из букв английского алфавита (или русского — это не имеет значения, можно в качестве объекта подсчета использовать любой символ из кодовой таблицы). Для этого в памяти нужно организовать таблицу, количество элементов в которой будет соответствовать количеству букв в алфавите. Далее необходимо составить программу, в которой текст будет анализироваться с помощью цепочечных команд. При этом нас интересуют разделяющие слова пробелы и первые буквы самих слов. Так как символы букв имеют определенное двоичное значение, то на его основе вычисляется адрес в таблице, по которому располагается элемент, в минимальном варианте состоящий из одного поля. В этом поле ведется подсчет количества слов в тексте, начинающихся с данной буквы. В следующей программе с клавиатуры вводится 20 слов (длиной не более 10 символов), производится подсчет английских слов, начинающихся с определенной строчной буквы, и результат подсчета выводится на экран. Хэш-функция (функция расстановки) имеет вид:
A=(C-97)*L,
где А — адрес в таблице, полученный на основе двоичного значения символа С; L — длина элемента таблицы (для нашей задачи L=l); 97 — десятичное смещение в кодовой таблице строчного символа «а» английского алфавита.
:prg02_07.asm - программа на ассемблере для подсчета количества слов, начинающихся
с определенной строчной буквы
:Вход: ввод с клавиатуры 20 слов (длиной не более 10 символов). -.Выход: вывод результата подсчета на экран.
buf_Oahstruc
len_bufdb 11 ; длина bufjn
lenjin db 0 действительная длина введенного слова (без учета Odh) bufjn db 11 dup (20h) -.буфер для ввода (с учетом Cdh) ends 1 .data
tabdb 26 dup (0) buf buf_0ah<>
db Odh.Oah,'$' ;для вывода функцией 09h (int 21h)
.code
-.вводим слова с клавиатуры
mov ex,20
lea dx.buf
movah.Oah ml: int 21h :анализируем первую букву введенного слова - вычисляем хэш-функцию: А=С*1-97
mov Ы , buf . bufjn sub Ы. 97 inc [bx] loop ml
:выводим результат подсчета на экран push ds popes
xor al ,al
lea di ,buf
mov ex.type bufjah rep stosb ; чистим буфер buf
mov ex.26 :синвол в buf.buf_1n
lea dx.buf
mcv Ы,97 m2: push bx
mov buf .bufjn.bi :опять вычисляем хэш-функцию:
А»С*1-97 и преобразуем "количество" в символьный вид
sub Ы. 97
mov al .[bx]
aam
or ax,03030h ;в ах длина в символьном виде
mov buf.len in.al —
mov buf.len_buf.ah ;теперь выводим:
mov ah, 09h
int 21h pop bx
inc Ы
loop m2
Таким образом, относительно сложная с первого взгляда задача очень просто реализуется с помощью методов хэширования. При этом обеспечивается высокая скорость выполнения операций доступа к элементам таблицы. Это обусловлено тем, что адреса, по которым располагаются элементы таблицы, являются результатами вычислений простых арифметических функций от содержимого соответствующих ключевых слов.
Перечислим области, где методы хэширования оказываются особенно эффективными.
Но на практике не все так гладко и оптимистично. Для эффективной и безотказной работы метода хэширования необходимо очень тщательно подходить как к изучению задачи на этапе ее постановки, так и к возможности использования конкретного алгоритма хэширования в контексте этой задачи. Так, на стадии изучения постановки задачи, в которой для доступа к табличным данным планируется использовать хэширование, требуется проводить тщательные исследования по направлениям: диапазон допустимых ключей, максимальное количество элементов в таблице, вероятность возникновения коллизий и т. д. При этом нужно знать как общие проблемы метода хэширования, так и частные проблемы конкретных алгоритмов хэширования. Одну из таких проблем рассмотрим на примере задачи.
Пусть необходимо подсчитать количество двухсимвольных английских слов в некотором тексте. В качестве хэш-функции для вычисления адреса можно предложить функцию подсчета суммы двух символов, умноженной на длину элемента таблицы: A=(Cl+C2)*L-97, где А — адрес в таблице, полученный на основе суммы двоичных значений символов С1 и С2; L — длина элемента таблицы; 97 — десятичное смещение в кодовой таблице строчного символа «а» английского алфавита. Проведем простые расчеты. Сумма двоичных значений двух символов 'а' равна 97+97=194, сумма двоичных значений двух символов 'г' равна 122+122=244. Если организовать хэш-таблицу, как в предыдущем случае, то получится, что в ней должно быть всего 50 элементов, чего явно недостаточно. Более того, для сочетаний типа ab и Ьа хэш-сумма соответствует одному числовому значению. В случае когда функция хэширования вычисляет одинаковый адрес для двух и более различных объектов, говорят, что произошла коллизия, или конфликт. Исправить положение можно введением допущений и ограничений, вплоть до замены используемой хэш-функции.
Программист может либо применить один из известных алгоритмов хэширования (что, по сути, означает использование определенной хэш-функции), либо изобрести свой алгоритм, наиболее точно отображающий специфику конкретной задачи. При этом необходимо понимать, что разработка хэш-функции происходит в два этапа.
2. Выбор алгоритма преобразования числовых значений в набор хэш-адресов.
Выбор способа перевода ключевых слов в числовую форму
Вся информация, вводимая в компьютер, кодируется в соответствии с одной из систем кодирования (таблиц кодировки). В большинстве таких систем символы (цифры, буквы, служебные знаки) представляются однобайтовыми двоичными числами. В последних версиях Windows (NT, 2000) используется система кодировки Unicode, в которой символы представляются в виде двухбайтовых двоичных величин. Как правило, ключевые поля элементов таблиц — строки символов, Наиболее известные алгоритмы закрытого хэширования основаны на следующих методах [32]:
Далее мы рассмотрим только первые четыре метода. Остальные методы — сегментации, перехода к новому основанию, алгебраического кодирования — мы рассматривать не будем. Отметим лишь, что их используют либо в случае значительной длины ключевых слов, либо когда ключ состоит из нескольких слов. Информацию об этих методах можно получить в литературе .
Рассмотрение методов хэширования будет произведено на примере одной задачи. Это позволит лучше понять их особенности, преимущества, недостатки и возможные ограничения.
Необходимо разработать программу — фрагмент компилятора, которая собирает информацию об идентификаторах программы. Предположим, что в программе может встретиться не более М различных имен. Длину возможных имен ограничим восьмью символами. В качестве ключа используются символы идентификатора, какие и сколько — будем уточнять для каждого из методов. Элемент таблицы состоит из 10 байт: 1 байт признаков, 1 байт для хранения длины идентификатора и 8 байт для хранения символов самого идентификатора.
Метод деления
Этот простой алгоритм закрытого хэширования основан на использовании остатка деления значения ключа К на число, равное или близкое к числу элементов таблицы М:
А(К) = К mod M
В результате деления образуется целый остаток А(К), который и принимается за индекс блока в таблице. Чтобы получить конечный адрес в памяти, нужно полученный индекс умножить на размер элемента в таблице. Для уменьшения коллизий необходимо соблюдать ряд условий:
Важно отметить случай, когда число элементов таблицы М является степенью основания машинной систем счисления (для микропроцессора Intel — это 2). Тогда операция деления (достаточно медленная) заменяется на несколько операций.
Метод умножения
Для этого метода нет ограничений на длину таблицы, свойственных методу деления. Вычисление хэш-адреса происходит в два этапа:
1. Вычисление нормализованного хэш-адреса в интервале [0..1] по формуле:
F(K) = (С*К) mod 1,
где С — некоторая константа из интервала [0..1], К — результат преобразования ключа в его числовое представление, mod 1 означает, что F(K) является дробной частью произведения С*К.
2. Конечный хэш-адрес А(К) вычисляется по формуле А(К) = [M*F(K)], где М — размер хэш-таблицы, а скобки [] означают целую часть результата умножения.
Удобно рассматривать эти две формулы вместе:
А(К) = М*(С*К) mod 1. (2.4)
Кнут в качестве значения С рекомендует использовать «золотое сечение» — величину, равную ((л/5)-1)/2«0,6180339887. Значение F(K) можно формировать с помощью как команд сопроцессора, так и целочисленных команд. Команды сопроцессора вам хорошо известны и трудностей с реализацией формулы (2.4) не возникает. Интерес представляет реализация вычисления А(К) с помощью целочисленных команд. Правда, в отличие от реализации сопроцессором здесь все же Удобнее ограничиться условием, когда М является степенью 2. Тогда процесс вычисления с использованием целочисленных команд выглядит так:
Выполняем произведение С*К. Для этого величину «золотого сечения» С~0, 6180339887 нужно интерпретировать как целочисленное значение,
обходимо стремиться к тому, чтобы появление 0 и 1 в выделяемых позициях было как можно более равновероятным. Здесь трудно дать рекомендации, просто нужно провести анализ как можно большего количества возможных ключей, разделив составляющие их байты на тетрады. Для формирования хэш-адреса нужно будет взять биты из тех тетрад (или полностью тетрады), значения в которых изменялись равномерно.
Метод квадрата
В литературе часто упоминается метод квадрата как один из первых методов генерации последовательностей псевдослучайных чисел. При этом он непременно подвергается критике за плохое качество генерируемых последовательностей. Но, как упомянуто выше, для процесса хэширования это не является недостатком. Более того, в ряде случаев это наиболее предпочтительный алгоритм вычисления значения хэш-функции. Суть метода проста: значение ключа возводится в квадрат, после чего берется необходимое количество средних битов результата. Возможны варианты — при различной длине ключа биты берутся с разных позиций. Для принятия решения об использовании метода квадрата для вычисления хэш-функции необходимо провести статистический анализ возможных значений ключей. Если они часто содержат большое количество нулевых битов, то это означает, что распределение значений битов в средней части квадрата ключа недостаточно равномерно. В этом случае использование метода квадрата неэффективно.
На этом мы закончим знакомство с методами хэширования, так как полное обсуждение этого вопроса не является предметом книги. Информацию об остальных методах (сегментации, перехода к новому основанию, алгебраического кодирования) можно получить из различных источников.
В ходе реализации хэширования с помощью методов деления и умножения возможные коллизии мы лишь обозначали без их обработки. Настало время разобраться с этим вопросом.
Обработка коллизий
Для обработки коллизий используются две группы методов:
Видно, что эти группы методов разрешения коллизий соответствуют классификации алгоритмов хэширования — они тоже делятся на открытые и закрытые. Яркий пример открытых методов — метод цепочек, который сам по себе является самостоятельным методом хэширования. Он несложен, и мы рассмотрим его несколько позже.
Закрытые методы разрешения коллизий более сложные. Их основная идея — при возникновении коллизии попытаться отыскать в хэш-таблице свободную ячейку. Процедуру поиска свободной ячейки называют пробитом, или рехэшировани-ем (вторичным хэшированием). При возникновении коллизии к первоначальному хэш-адресу А(К) добавляется некоторое значение р, и вычисляется выражение (2.5). Если новый хэш-адрес А(К) опять вызывает коллизию, то (2.5) вычисляется при р2, и так далее:
А(К) = (A(K)+Pi)mod М (I = 0..М). (2.5)
push ds popes
lea si .buf.len_in
mov cl .buf .lenjn
inccx :длину тоже нужно захватить
add di .lenjd repmovsb
jmp ml displ: :выводим идентификатор, вызвавший коллизию, на экран
рехэширование
;ищем место для идентификатора, вызвавшего коллизию в таблице, путем линейного рехэширования i nc bx mov ax.bx jmp m5
Квадратичное рехэширование
Процедура квадратичного рехэширования предполагает, что процесс поиска резервных ячеек производится с использованием некоторой квадратичной функции, например такой:
Pi = а,2+Ь,+с. (2.6)
Хотя значения а, Ь, с можно задавать любыми, велика вероятность быстрого зацикливания значений р(. Поэтому в качестве рекомендации опишем один из вариантов реализации процедуры квадратичного рехэширования, позволяющий осуществить перебор всех элементов хэш-таблицы [32]. Для этого значения в формуле (2.6) положим равными: а=1,Ь = с = 0. Размер таблицы желательно задавать равным простому числу, которое определяется формулой М = 4п+3, где п — целое число. Для вычисления значений р> используют одно из соотношений:
pi = (K+i2)modM. (2.7)
Pi = [M+2K-(K+i2)modM]modM. (2.8)
где i = 1, 2, ..., (M-l)/2; К — первоначально вычисленный хэш-адрес.
Адреса, формируемые с использованием формулы (2.7), покрывают половину хэш-таблицы, а адреса, формируемые с использованием формулы (2.8), — вторую половину. Практически реализовать данный метод можно следующей процедурой.
Программа та же, что приведена в методе линейного рехэширования, за исключением добавления одной команды для инициализации процесса рехэширования, самого фрагмента рехэширования и небольших изменений сегмента данных. могут являться методы, основанные на деревьях поиска, и т. п. Наибольший эффект от хеширования — при поиске по заданным идентификаторам или дескрипторам, что характерно для задач баз данных, обработки документов и т. д. Для задач, в которых поиск ведется сравнением или вычислением сложных логических функций, лучше использовать традиционные методы сортировки и поиска.
Для того чтобы совершить плавный переход к рассмотрению следующей структуры данных — спискам, вернемся еще раз к одной проблеме, связанной с массивами. Упоминалось, что среди массивов можно выделить массивы специального вида, которые называют разреженными. В этих массивах большинство элементов равны нулю. Отводить место для хранения всех элементов расточительно. Естественно, возникает желание сэкономить. Что для этого можно предпринять?
Техника обработки массивов предполагает, что все элементы расположены в соседних ячейках памяти. Для ряда приложений это недопустимое ограничение.
Обобщенно можно сказать, что все перечисленные выше структуры имеют общие свойства:
Исходя из этих свойств данные структуры данных и называют статическими. Снять подобные ограничения можно, используя другой тип данных — списки. Для них подобных ограничений не существует.